
In der letzten Situng vom 22.01.2016 haben wir uns mit, dem viel gewünschten Thema, Big Data, an Hand des Textes von Dana Boyd und Kate Crawford, beschäftigt. Er stellt eine relativ leichten Einstieg in das komplexe Themenfeld von Big Data da und behandelt deren Grundlegenden Ideen. Im Seminar haben wir nur erst einzeln dann gruppenweise hierarchische Mindmaps erstellt um diese Grundgedanken einmal zu visualisiern und aus zu differenzieren. Und dies sind die Ergebnisse:
Gruppe 1:
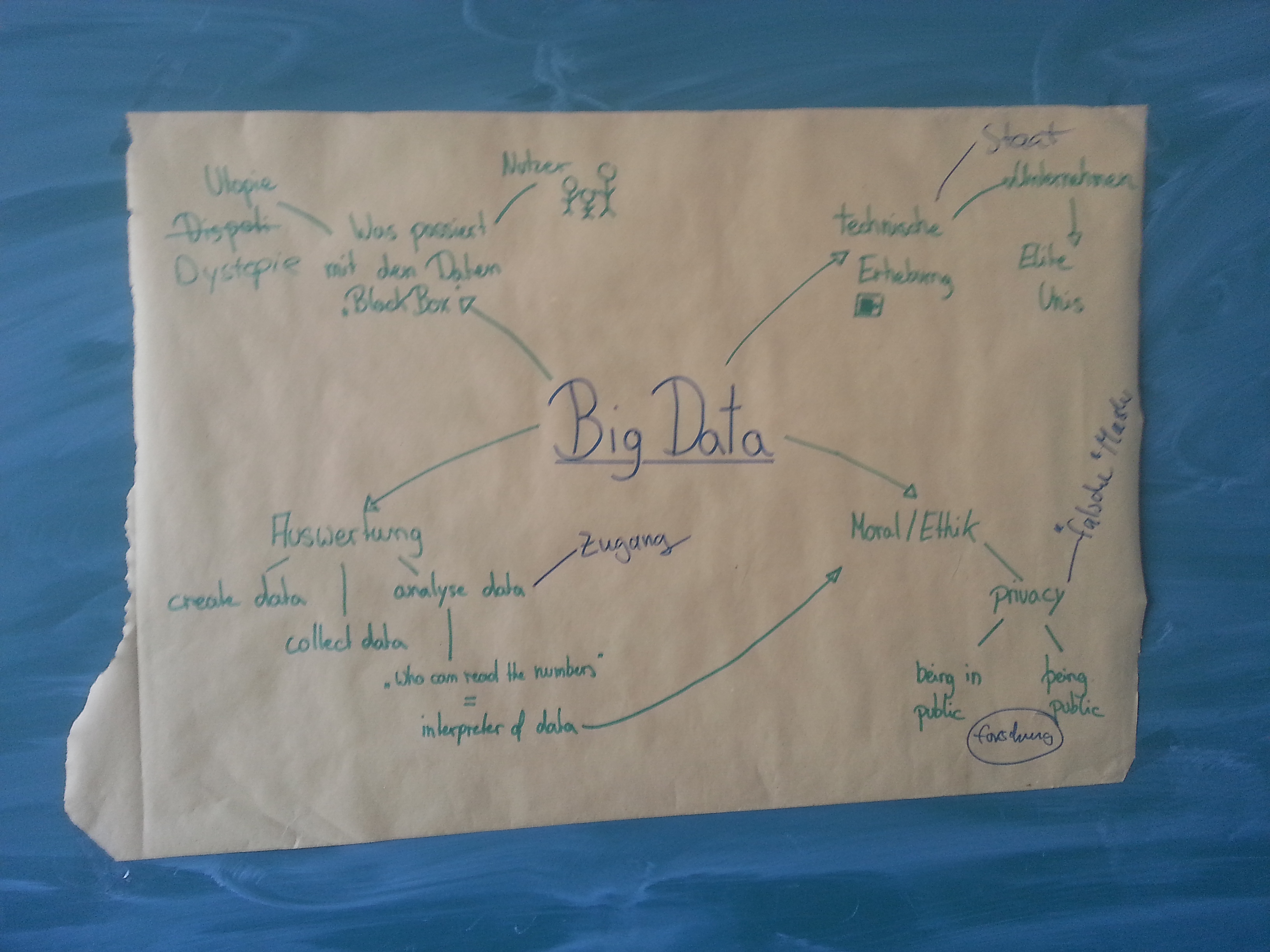
Gruppe 2:

Interessant finde ich hier bei vor allem, dass die beiden Gruppen recht untschiedliche Gegenstände als relevant erachtet haben, so sieht man, dass die Gruppe 1 ethisch/moralische Aspekte (z.B: „be in public vs. be public“) an Big Data für wesentliche Kritikpunktehält. Dieser Aspekt war Gruppe 2 anscheinend nicht all zu wichtig, dafür haben sie den Aspekt der Richtigkeit der Aswertung betont,wie zum Beispiel die wichtige Erkenntnis aus der Stochastik, dass man aus Korrelationen keine Kausalitäten folgern kann, die leider bei Big Data leider oft nicht beherzigt wird.
Post-Privacy
Im Laufe der Vorstellung der Ergebnisse fiel dann auch der Begriff der Post-Privacy, welchen ich persönlich sehr interessant fand. In der Post-Privacy geht man davon aus, dass es mittlerweile unmöglich ist Privatheit im Netz zu gewährleisten und kommt deswegen zu dem Schluss, dass Datenschutz, in dem Ausmaße wie wir ihn verstehen, größtenteils überholt ist und forden im Gegensatz zu Datenschützern mehr Transparenz im Netz und weniger Regulierung durch den Staat. Also quasi das Internet als einen rechtsfeien Raum in dem jede*r User transparent ist, vor allem auch untereinander. Befürworter sehen darin eine Plattform für Meinungsfreiheit und sehen in Post-Privacy, wie schon angedeutet, die einzige Alternative zu dem vorherrschenden Privacy-Konzept, welches, laut der Befürworter, nicht mehr durchsetzbar ist. Diese Meinung, dass Datenschutz in Zeiten von Big Data und „Internet-Riesen“ nicht mehr umgesetzt werden kann oder wenn ungenügend, sind auch viele Datenschützer und somit Kritiker der Post-Privacy, jedoch empfehlen diese den Usern eher Strategien zur Datensparsamkeit und Datenvermeidung anstatt von „Datenstriptease“. Weitere Arguemente der Datenschützer gegen Post-Privacy sind unter anderem, die Unterschätzung der Konzerne als „Datenkraken“ und, dass sich durch die Transparenz gepaart mit Gruppendynamiken Meinungsfreiheit eher eingeschränkt würde als gefördert.
Beide Seiten haben Punkte für sich und gegen sich, was für mich heißt, dass diese Debatte auf jeden Fall weiter verfolgt werden sollte und wir uns alle fragen sollten in welche Richtung wir selbst tendieren und in wie fern denn Datenschutz im Internet wirklich realisierbar ist.
(Korrigiert mich falls ich falsch liege, aber wenn ich, dass richtig sehe dann ist diese ganze Post-Privacy Debatte sogar ein recht lokales Phänomen. Finde ich äußerst interessant. :D)
https://www.taz.de/!5102603/
https://www.spiegel.de/netzwelt/netzpolitik/internet-exhibitionisten-spackeria-privatsphaere-ist-sowas-von-eighties-a-749831.html
Am 27. Januar 2016 um 13:41 Uhr
Ich finde die Post-Privacy Debatte auch sehr interessant, da sie hoch aktuell ist und jeden etwas angeht. Da sich niemand der Nutzung des World Wide Web entziehen kann.
In meinen Augen ist es schwierig die Daten im Netz so zu schützen, wie es die Vetreter dieser Theorie wollen. Es gibt einfach zu viele Informationen über jede einzelne Person im Netz. Diese können gar nicht mehr alle geschützt werden.
Eine wesentlich sinnvollere Lösung, sehe ich auf der anderen Seite. Da es im Internet sowieso fast unmöglich ist Recht und Gesetz durchzusetzten, sollte man es gleich lassen und herum drehen. Wenn jeder User Zugang zu allen Infos hat, weil Transparenz die Internetwelt bestimmt, könnte es zu einer Selbstregulierung kommen, die Gesetze erübrigt. Natürlich muss man das Problem sehen, dass nicht alle User gleichermaßen die Fähigkeiten haben gewisse Daten richtig auszuwerten und so wieder ein Ungleichgewicht entsteht.
Schlussendlich muss ich sagen das es sinnvoller wäre diesem Ungleichgewicht entgegen zu wirken, anstatt mit Gesetzen zu versuchen ein Chaos zu Ordnung.
Am 27. Januar 2016 um 13:50 Uhr
Auch ich finde die Vorstellung des Begriffes Post Privacy sehr spannend. Wie du ja bereits dargestellt hast haben die unterschiedlichen Positionen viele Vor- und Nachteile, dennoch würde ich eher eine Gegenposition einnehmen. Denn mir ist noch nicht ganz klar, was Post Privacy für mich bedeuten würde. Müsste ich meine Daten freiwillig allen zugänglich machen, damit es eine „Gleichberechtigung“ im Netz gibt? Um ehrlich zu sein sehe ich dann keinen großen Unterschied zu dem wie es jetzt läuft. Auch zu Zeiten von Post Privacy wird es Menschen geben, die so technisch versiert sind, dass sie viele Informationen aus dem Internet beziehen können ohne welche geben zu müssen. Und was haben wir dann? Richtig das gleiche Problem, nur das diesen Leuten dann noch mehr Daten und Möglichkeiten offen stehen. Was auch die Frage nach der Regulierung durch den Staat in meinen Augen sinnlos macht, denn entweder er setzt Datenschutzbestimmungen durch und schränkt somit das Internet ein- oder er späht uns alle noch stärker aus als ehe schon. Was haben wir also mit Post Privacy gewonnen? Die ganze Debatte erinnert ein bisschen an das „Nothing to hide“ Argument – dort geben wir unsere privaten Daten für eventuelle Sicherheit auf. Wofür geben wir bei Post Privacy unsere Daten auf? Für ein eventuell freies Internet? Also wenn das die Konsequenz ist, dann Nein Danke!
Am 29. Januar 2016 um 00:16 Uhr
Leider habe ich die Seminardiskussion zu Post Privacy verpasst, aber auf diesem Weg kann ich ja doch noch teilnehmen.
Zuerst sei gesagt, dass mir die Rhetorik von „wir brauchen mehr Transparenz, da Privatheit ohnehin nur ungenügend umgesetzt werden kann“ nicht ausreicht. Hier artikuliert sich weder eine normative noch juristisch begründete Position, sondern Defätismus. Wer soll denn dafür sorgen, dass Privatheit im Netz umsetzbar bleibt, wenn nicht Datenschützer gemeinsam mit IT-Experten? Datenschützer, die so argumentieren, entledigen sich ihrer Existenzgrundlage.
Erst heute hat die ZEIT einen Artikel veröffentlicht zu den Verhandlungen zwischen der EU-Kommission und Vertreten der US-Regierung zu einem neuen Datenabkommen: https://www.zeit.de/digital/datenschutz/2016-01/datenschutz-safe-harbor-2-abkommen-eu-usa.
Interessanter Weise greift der Artikel einige der Argumente auf, die ihr dargelegt habt. So fordert die EU mehr Transparenz und möchte, dass EU-Bürger einsehen können, wer ihre Daten angefragt hat. Zugleich sollen US-Behörden dahingehend transparenter werden, dass ihr Datenzugriff von einer weiteren Instanz kontrolliert wird. Das soll die Einseitigkeit des „beobachtenden Blicks“ einschränken.
Alexander Dix, der Berliner Datenschutzbeauftragten, sieht dagegen die Unternehmen in der Pflicht, die Privatsphäre ihrer Nutzer besser zu schützen, beispielsweise durch Datenverarbeitung in Europa mit seinen strengeren Datenschutzrichtlinien. Und die Unternehmen sagen – welch Überraschung – dass das angesichts der Menge der Daten „kaum umsetzbar“ sei. Und tatsächlich haben sie vielleicht sogar recht, wenn auch nicht nur aufgrund der Menge der Daten. Aktuell läuft in den USA ein Gerichtsverfahren, in dem die US-Behörden versuchen, ihre Zugriffsrechte auch auf Server auszuweiten, die im Ausland stehen. Wenn dies gelingt, sind nationale Datenschutzrichtlinien wertlos.
Bleibt also doch nur totale Transparenz?
Am 8. Februar 2016 um 23:28 Uhr
Auch ich habe Probleme mit Post Privacy. Es scheint mir nicht schlüssig, dass durch eine Art gleichberechtigte Datenfreigabe etwas verbessert wird. Jeder Mensch hat gewisse Persönlichkeitsrechte und diese sollten auch im digitalen Zeitalter gewahrt werden. Bereits jetzt haben Geheimdienste und große Unternehmen ohne unser Wissen Zugriff auf wahnsinnige Datenmengen und kriegen diese doch bestens für ihre Zwecke organisiert ohne Spuren von sich selbst frei zu geben. Wie soll es dann werden, wenn alle ihre Daten freigeben? Denn die Profiteure werden Wege finden, unerkannt zu bleiben.
Resignierend könnte man sagen, dass sich so schnell keine Lösung ergeben wird, da viel zu viele mächtige Parteien im Spiel sind, die entschieden gegen jegliche Einschränkungen kämpfen. Doch ich denke, dass es sich immer lohnt, seine Daten so gut man eben kann zu schützen.
Am 10. Februar 2016 um 16:30 Uhr
Ich würde im Rahmen dieser kleinen Post-Privacy-Debatte gern nochmal den Blick Richtung Big Data lenken. Eine der für mich wichtigsten neu gelernten Informationen des Seminars ist die „Problematik“ die aus der statistischen Einschätzung von Informationen über Personen entsteht.
Datenschutz war bisher für mich immer, „Ich gebe meiner Krankenkasse meine Daten und die passen dann auf, dass keiner sonst die sehen kann und verteilen die auch nicht in der Weltgeschichte“. Das war der eine Aspekt, der sich auf von mir freiwillig gegebene Datensätze bezieht. Dann gab es noch den Aspekt der Spuren die ich über meine IP, Cookies, Browserfingerprint im Internet mehr oder weniger unfreiwillig hinterlasse.
Der erste Aspekt lag aus meiner Sicht wesentlich in der Verantwortung von Staat und Unternehmen. Für den zweiten wär das im Prinzip auch denkbar, aufgrund mangelnder Gesetzeslage lag das aber bisher in der Verantwortund jedes Einzelnen.
Was ich neu gelernt habe ist, dass die Unternehmen ihre riesigen Statistiken nutzen und einzelne aufgrund bestimmter Merkmale (wie Alter oder Geschlecht) diskriminiert werden können. Hätte man auch drauf kommen können.
Dieser „neue“ Aspekt ist aus meiner Sicht der, auf den sich die Post-Privacy-Debatte konzentriert (konzentrieren sollte), die anderen Aspekte sind Informationen die direkt auf mich persönlich zutreffen und deren Geheimhaltung üblicherweise bestimmte Funktionen erfüllt und die auch für Wissenschaftler nicht besonders interessant sind. Die großen Datenbanken von Informationen, die nicht an bestimmte Personen gebunden sind, die Google oder Facebook erheben wären für den öffentlichen Zugang schon interessanter. Datenschützer wollen vielleicht klassischerweise, dass große Unternehmen solche Praktiken einstellen, aber vielleicht ist es hier sinnvoll eher in die andere Richtung zu gehen und die Unternehmen zu zwingen diese Daten für die Forschung zugänglich zu machen. Diese Daten könnten uns allen nützen wenn sie für die Wissenschaft zur Verfügung stünden unter der Voraussetzung, dass man sie richtig zu interpretieren weiß. Das wäre auch ein positiver Effekt, die Auswertung der Daten würde nicht mehr monopolistisch efolgen, sondern es könnte einen Diskurs darüber geben.
Am 21. Februar 2016 um 10:09 Uhr
Big Data
Besonders spannend bei der Diskussion über Big Data finde ich den Diskurs, zwischen Daten sammeln und Daten auswerten.
Das unsere Daten gesammelt werden scheint für Viele erst einmal nicht weiter schlimm. Soll doch dokumentiert werden was wir bei amazon bestellen oder wohin wir in den Urlaub fahren.
Dennoch bleibt ein Unbehagen zurück. Das Gefühl einer Überwachung, kann das Gefühl schüren sich nicht frei bewegen zu können.
Zwar sitzt kein Mensch am anderen Ende der Leitung ( Wie beispielsweise von der Stasi in der DDR), der in unsere Privatsphäre eindringt, jedoch werden unsere Daten ausgewertet.
Nicht von Menschen, sondern von Computern.
Die erhobenen Daten werden aggregiert und Algorithmen ziehen daraus Rückschlüsse. Rückschlüsse, welche Werbeanzeige einem angezeigt werden sollte oder welche Suchergebnis zuerst bei Google gelistet wird.
Für mich persönlich stellt sich in diesem Kontext die Frage, wie gleich sind wir dadurch im Web?
Die größte Gefahr sehe ich darin, dass die Big-Data Analysen annahmen, über Personen produzieren, auch wenn diese nicht unbedingt zutreffend sind. Schließlich arbeiten die Algorithmen ja selbst nur mit Variablen aus denen sie dann ihr Ergebnis generieren.
Die Erkenntnisse die eine Maschine ausspuckt, ist immer nur eine mögliche Schlussfolgerung; basierend auf Handlungen, die jemand im Internet getätigt hat. Das Handeln des Individuums wird nicht in einen Kontext gesetzt. Darum geht es bei BigData auch gar nicht. Solange 40 Prozent der Daten zutreffen, scheint es sich um eine valide Auswertung zu handeln. Eine Vorgabe, die ich für sehr bedenklich halte.
Für mich persönlich stellt sich in diesem Kontext die Frage, wie gleich sind wir dadurch im Web? Die größte Gefahr sehe ich darin, dass die Big Data-analysen annahmen, über Personen produzieren, auch wenn diese nicht unbedingt zutreffend sind. Schließlich arbeiten die Algorithmen ja selbst nur mit Variablen aus denen sie dann ihr Ergebnis generieren.
Die Erkenntnisse, die eine Maschine ausspuckt, ist immer nur eine mögliche Schlussfolgerung – basierend auf Handlungen, die jemand im Internet getätigt hat. Das Handeln des Individuums wird nicht in einen Kontext gesetzt. Darum geht es bei BigData auch gar nicht. Solange 40 Prozent der Daten zutreffen, scheint es sich um eine valide Auswertung zu handeln. Eine Vorgabe, die ich für sehr bedenklich halte.
Einen weiteren elementaren Teil der Debatte scheint für mich die Offenlegung der Daten und der Zugriff der Nutzer auf ihre eigenen Daten zu sein. Nur in dem die Erhebung und Nutzung der Daten offengelegt wird, kann der Nutzer entscheiden, ob er damit einverstanden ist. Doch reicht das aus? Denn oft Stimmen Leute einfach nur zu, ohne die dahinter stehenden Zustimmungserklärungen zu lesen. Womit wir wieder am Anfang der Debatte sind.