Alice Cheng / Andreas Guder
1. Einleitung
Für sprachwissenschaftliche Untersuchungen ist es im Allgemeinen notwendig, authentische Sprachäußerungen in die Analyse miteinzubeziehen, um grammatische Theorien aufzuzeigen, Hypothesen zu entwickeln oder Belege für Hypothesen vorzuweisen. Dazu müssen jedoch erst möglichst authentische Daten vorhanden sein, die erhoben, aufbereitet und ausgewertet werden. Um diesen Schritt zu umgehen, empfiehlt es sich, mit bereits existierenden Korpora zu arbeiten. Bei Korpora (Singular: das Korpus) handelt es sich um Sammlungen von sprachlichen Daten, die mit einer integrierten Suchmaschine ausgestattet sind und so das Erforschen der Verwendungskontexte und Verwendungsweisen bestimmter Wörter, grammatischer Strukturen oder Phrasen vereinfachen sollen. Die Nutzung von Korpora für sprachwissenschaftliche Zwecke wird als Korpuslinguistik bezeichnet.
Dieser Text soll einen kurzen Einstieg in die Korpuslinguistik darstellen und die grundlegenden Fragen beantworten, wie: Was sind Korpora? Wie sind sie aufgebaut und wie kann ich sie in meiner Forschung verwenden? Darüber hinaus soll eine Übersicht der online verfügbaren Chinesischkorpora helfen, ein geeignetes Korpus für das eigene Forschungsvorhaben zu finden.
2. Hauptteil
2.1 Beschreibung und Aufbau von Korpora
Bei einem Korpus handelt es sich allgemein um „eine Sammlung schriftlicher oder gesprochener Äußerungen.“ (Lemnitzer/Zinsmeister 2015, S. 13). Die gesammelten Texte, die auch als Primärdaten bezeichnet werden, können mit Metadaten angereichert werden, die Auskunft über Autoren, Entstehung und Quelle des Textes geben. Zudem gibt es linguistische Annotationen, die je nach Fragestellung und Zweck des Korpus variieren können. (vgl. Lemnitzer/Zinsmeister 2015, S. 13). Darüber hinaus sind Korpora mit einem integrierten Korpusrecherchesystem ausgestattet, um Sprachanalysen durchzuführen. Ein Korpus unterscheidet sich folglich von einem Textarchiv dadurch, dass es eine Recherchesoftware und linguistische Annotationen enthält (vgl. Storrer 2011, S. 225). Für die Erstellung eines Korpus werden die Primärtexte zunächst in Einheiten wie Abschnitte, Sätze oder einzelne Worteinheiten segmentiert (tokenisierung) und anschließend mit Annotationskategorien (tags) versehen. Die zerlegten Einheiten, die nicht nur Wörter, sondern auch alle Satzzeichen, Zahlen und Symbole umfassen, werden token genannt. Der Beispielsatz to be or not to be that is the question enthält somit zehn token. Davon zu unterscheiden ist die ‘Wortform‘, bei der ausschließlich die Form des tokens betrachtet wird. Dabei werden gleiche Wortformen als eine Einheit gezählt. Demnach gibt es im oben genannten Beispielsatz acht Wortformen. Zudem gibt es noch den Begriff ‚Lexem‘ oder ‚Lemma‘, welcher sich auf den semantischen Aspekt des Wortes bezieht. In flektierenden Sprachen enthalten Lexeme mehrere Wortformen, da unterschiedliche Flexionsendungen für ein Lexem vorhanden sind. Demzufolge gehören in dem Beispiel auch to be und is zu demselben Lexem. Der Satz enthält folglich sieben Lexeme (vgl. Storrer 2011, S. 217f). Die Recherche in Korpora basiert vorwiegend auf Wortformen. Um jedoch gleich aussehende Wortformen unterschiedlicher Lexeme bei Suchergebnissen zu unterscheiden, z.B. 都 (dou1) mit der Bedeutung „alle“ und 都 (du1) von 首都 „Hauptstadt“, wird die Wortartenannotation, auch part-of-speech tag oder POS-tagging genannt, eingesetzt. Damit wird jedes token mit einem tag versehen, das für die jeweilige syntaktische Kategorie steht (vgl. Storrer 2011, S. 219). Mit dieser Annotation ist es beispielsweise möglich, 都 (dou1) eindeutig als Adverb und 都 (du1) als Nomen zu kategorisieren.
2.2 Datensammlung & Repräsentativität von Korpora
Es gibt zwei Arten von Korpora, die sich hinsichtlich ihrer Datensammlung voneinander unterscheiden: monitor corpus und balanced corpus, auch sample corpus genannt. Beim monitor corpus handelt es sich um ein Korpus, dessen Datenmenge kontinuierlich erweitert wird. Der Vorteil eines solchen monitor corpus ist die zunehmende Ausgewogenheit der Daten, da davon ausgegangen wird, dass das Korpus sich aufgrund der stetig wachsenden Daten selbst reguliert. Das balanced corpus hingegen enthält nur eine begrenzte, jedoch sorgfältig ausgewählte Datenmenge, die versucht, eine bestimmte Sprache während einer bestimmten Zeitspanne zu repräsentieren. Dies bedeutet, dass für die Untersuchung irrelevante Texte aussortiert und der Umfang des Korpus begrenzt wird. Einige Beispiele für balanced corpora sind der LOB (Lancaster-Oslo/Bergen) Korpus und die Korpora der Brown family. Sie basieren alle auf dem gleichen Korpusdesign und haben somit den gleichen Größenumfang von etwa 1 Million Wörtern sowie die gleiche Anzahl an Textsorten, die aus denselben oder ähnlichen thematischen Domänen (sampling frame) stammen. Solche balanced corpora ermöglichen neben diachronischen Untersuchungen von Sprachen auch Vergleiche zwischen Sprachen (vgl. McEnery/Hardie 2012, S. 8f).
2.3 Korpuslinguistik
Je nach Forschungsansatz und Erkenntnisinteresse unterscheidet sich der Einsatz von Korpora (siehe Tabelle 1): es gibt einen quantitativen Ansatz, einen quantitativ-qualitativen Ansatz (corpus-based) und den lediglich korpusgestützten Ansatz (corpus-driven). (McEnery/Hardie 2012, S. 6)
| Korpusbasiert quantitativ | Korpusbasiert, quantitativ-qualitativ | Korpusgestützt | |
| Theoretischer Rahmen | (nicht anwendbar) | Kontextualismus (Firth) | Strukturalismus (Saussure)/ Generative Grammatik (Chomsky) |
| Erkenntnis-theoretischer Ansatz | Extrem empirisch | Gemäßigt empirisch | Rationalistisch |
| Primäre linguistische Domäne | Statistische Sprachmodelle | Semantik | Syntax |
| Anwendungsgebiete | Informations-erschließung, Verarbeitung gesprochener Sprache | Lexikographie, Fremdsprachen-unterricht, Übersetzungs-wissenschaft | Theoretische Linguistik |
Tabelle 1: Korpusanalysen (verkürzt u. übernommen aus Lemnitzer/Zinsmeister 2015, S. 34)
Beim quantitativen Ansatz werden die Rohdaten eines Korpus verwendet, um quantitative Daten zu ermitteln, beispielsweise mit welcher absoluten oder relativen Häufigkeit ein bestimmtes Wort in einem Text oder dem Korpus vorkommt. Dieser Ansatz wird insbesondere im Anwendungsgebiet der Informationserschließung und der Verarbeitung gesprochener Sprache für texttechnologische bzw. computerlinguistische Anwendungen eingesetzt (Lemnitzer/Zinsmeister 2015, S. 35). Im Unterschied dazu ist das Ziel des quantitativ-qualitativen Ansatzes, nicht nur die Daten quantitativ zu erheben, sondern sie auch zu interpretieren, um Verallgemeinerungen aus den beobachtbaren Daten abzuleiten. Relevante Anwendungsgebiete sind hier die Lexikographie, der Fremdsprachenunterricht und die Übersetzungswissenschaft.
Bei korpusgestützten Ansätzen werden die Korpusdaten meist nur herangezogen, um Sprachtheorien zu belegen, zu falsifizieren oder nach bestimmten syntaktischen Strukturen zu suchen. Aus diesem Grund beschränkt sich der Einsatzbereich des korpusgestützten Ansatzes eher auf die theoretische Linguistik (vgl. Lemnitzer/Zinsmeister 2015, S.37).
2.4 Forschungsfragen und Analysebeispiel
Hinsichtlich der chinesischen Sprache kann man mithilfe von Korpora beispielsweise untersuchen, in welchen Kontexten bestimmte Wörter oder Strukturen auftreten, wie sich die chinesische Sprache im Lauf der Zeit verändert oder welche Wortneuschöpfungen es gibt. Man kann auch verschiedene Textsorten anhand der in ihren vorkommenden Wörter vergleichen.
Mit sogenannten Lernerkorpora ist es darüber hinaus möglich, zu untersuchen, welche grammatischen Fehler Chinesischlernende häufig machen, um diese für die Fremdsprachendidaktik zu generalisieren.
Um die Verwendung einer quantitativ-qualitativen korpusbasierten Analyse vorzustellen, wird exemplarisch das Vorkommen der 把 Ba-Struktur im chinesischen Sprachgebrauch untersucht. Zunächst spielen für die Auswahl des Korpus folgende Aspekte eine Rolle: das Medium (schriftlich/mündlich), der Zeitraum, aus dem die sprachlichen Daten stammen, sowie Größe und die Textsorte(n) des Korpus, um eine maximale Validität der Analyse zu erreichen. Würde beispielsweise ein schriftliches Korpus herangezogen, das ausschließlich aus klassisch-literarischen Texten der Qing-Zeit bestünde, wäre das Ergebnis der Untersuchung weder valide noch repräsentativ für den gesamten Sprachgebrauch des Chinesischen. Gleiches gilt für die Größe des Korpus: Je größer und ausgewogener die Datenmenge des Korpus, desto reliabler ist das Analyseergebnis.
Im vorliegenden Fall beschränkt sich unser Ziel auf die Analyse der Verwendung von 把 im schriftlichen Chinesisch des 21. Jahrhunderts. Dafür ist eine ausgewogene und repräsentative Stichprobe notwendig. Basierend auf diesen Überlegungen wurde das UCLA Korpus (Xu/Wu 2014) ausgewählt, welches aufgrund des BROWN family Korpusdesigns verschiedene Textsorten und Genres enthält und möglichst ausgewogen gestaltet wurde.
Gibt man nun 把 in die Suchleiste des UCLA Korpus ein, erscheinen in der Treffermenge alle Ergebnisse, die die Wortform 把 enthalten. Neben der grammatischen Ba-Struktur werden folglich auch 把 als ZEW und Lexeme wie 把握,把式,把戏 etc. aufgelistet. Möchte man nur die 把-Struktur finden, lohnt es sich bei der Funktion „Word lookup“ zu suchen, wie viele Wortfomen das Zeichen 把 enthalten.
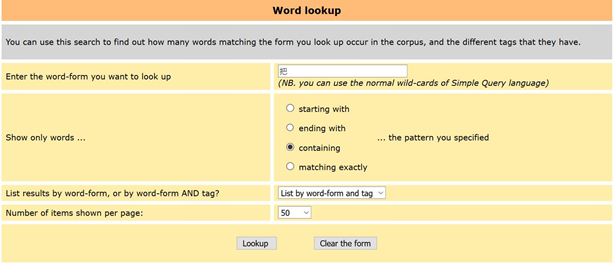
Abbildung 1: Ausschnitt der Word lookup Funktion des UCLA Korpus
Gibt man bei der Suche „List by word-form and tag“ an, werden die Ergebnisse mit ihren syntaktischen Kategorien angezeigt. Unter den Treffern lässt sich das syntaktische 把 nun leicht herausfiltern (85,24%). Den Ergebnissen kann darüber hinaus entnommen werden, mit welcher Häufigkeit das Zeichen 把 in den jeweiligen Wortformen und syntaktischen Kategorien auftritt. Klickt man auf 把 _p werden ausschließlich Sätze angezeigt, die die 把-Struktur enthalten.
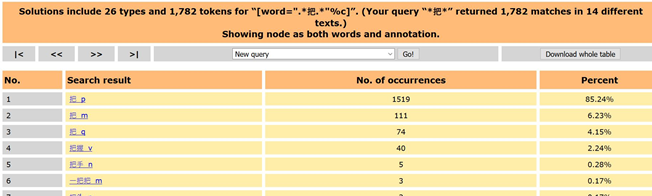
Eine andere Möglichkeit, die Suchanfrage zu präzisieren, ist die Untersuchung der Syntax. Man kann mit bestimmten Eingabemustern, wie bei einer Suchmaschine, die Suche eingrenzen (siehe dazu auch Storrer 2011, S. 222f und Lemnitzer/Zinsmeister 2015, S. 92f). Das UCLA Korpus enthält hierfür eine Übersicht der „simple query language syntax“, die bei der Eingabe der Suchanfrage aufgerufen werden kann. Für die Untersuchung der 把-Struktur kann bei der Suchmaske somit auch 把_p eingegeben werden, damit nur jene Wortformen mit der syntaktischen Einheit ‚Präposition‘ angezeigt werden. Damit werden 把 als ZEW oder Verb nicht in der Trefferliste aufgeführt.
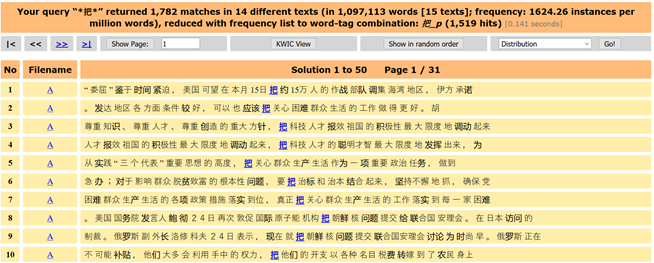
Abbildung 3: Ausschnitt einer Trefferliste zur Suchanfrage 把_p
Möchte man untersuchen, in welchen Textsorten die 把-Struktur auftritt, kann rechts oben unter „Distribution“ deren Verteilung angezeigt werden. In der Übersicht werden alle Kategorien sowie die jeweilige Trefferanzahl für die 把-Struktur aufgelistet.
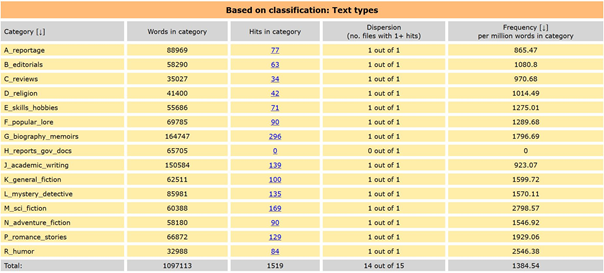
Abbildung 4: Ergebnisse für Verteilung der 把-Struktur nach Textsorten
Aus der Tabelle geht hervor, dass die untersuchte Struktur in nahezu allen Textsorten auftritt. Lediglich in der Kategorie Reports and official government documents gibt es keinen Treffer. Des Weiteren kann anhand der Verteilung auch die relative Häufigkeit der 把- Struktur abgelesen werden. Am häufigsten kommt sie demnach in den literarischen populären Textsorten science fiction, humor und romance stories vor. Texte aus der Presse wie reportage, editorials und reviews, aber auch academic writing weisen einen vergleichsweise geringen Gebrauch der 把-Struktur auf.
Ausgehend von diesen Ergebnissen kann die Hypothese formuliert werden, dass die 把-Struktur in schriftlichen Texten besonders häufig in literarischen Unterhaltungstexten auftritt. In schriftsprachlichen Textsorten des gehobenen Registers wird 把 hingegen seltener verwendet. Zur weiteren Untersuchung könnte nun beispielsweise ein mündliches Korpus herangezogen werden, um den Gebrauch der 把-Struktur im mündlichen Chinesisch mit diesen Ergebnissen zu vergleichen. Des Weiteren könnte man auch die Verwendung des gleichermaßen verwendeten, aber stärker schriftsprachlichen 将 jiang1 mit 把 ba3 kontrastieren.
2.5 Einschränkungen
Natürlich ist der Nutzen der Korpuslinguistik begrenzt; zwar bietet sie wertvolle Einblicke für die Fremdsprachenforschung und kann in Kombination mit anderen Forschungsmethoden genutzt werden, um ein umfassenderes Verständnis von Sprache und Kommunikation zu entwickeln, auf der anderen Seite sind jedoch folgende Punkte immer zu bedenken:
- Korpora sind nur so gut wie die Daten, die in sie eingespeist werden. Wenn die Daten nicht ausreichend repräsentativ sind, können die daraus abgeleiteten Erkenntnisse verzerrt sein. Insbesondere hinsichtlich Mündlichkeit sind chinesische Korpora oft wenig aussagekräftig.
- Korpuslinguistik ist besonders nützlich für die Untersuchung von häufig auftretenden sprachlichen Phänomenen. Seltene oder stark kontextabhängige Phänomene sind jedoch schwerer zu erfassen.
- Mangelnde Kontrolle über Kontext und Kommunikationssituation: In Korpora sind Texte oft aus ihrem ursprünglichen Kontext gerissen, was dazu führen kann, dass wichtige Informationen über die Kommunikationssituation verloren gehen, wodurch die Interpretation erschwert wird. Korpora sind in der Regel besser geeignet, um syntaktische und lexikalische Phänomene zu untersuchen. Die Erforschung von pragmatischen, bedeutungsbezogenen bzw. kulturspezifischen Kommunikationssituationen ist mit Korpusuntersuchungen kaum zu leisten.
- Wie überall kann auch der Faktor „Mensch“ zu unterschiedlichen subjektiven Urteilen und unterschiedlichen Interpretationen der Daten führen.
- Korpora können zeigen, dass bestimmte sprachliche Phänomene in der Realität auftreten, aber sie bieten oft keine direkten Einblicke in die Gründe dafür. Ursache-Wirkungs-Zusammenhänge müssen oft durch zusätzliche Forschungsmethoden ermittelt werden.
- Sprache entwickelt sich kontinuierlich, und Korpora können möglicherweise nicht immer aktuelle Trends oder Veränderungen in der Sprache erfassen. So basiert das vergleichsweise gut dokumentierte, nur in Print vorliegende 现代汉语频率词典 (BLCU 1986) aus Texten der frühen 1980er Jahre der VR China, die in journalistische, wissenschaftliche, mündliche (Theaterstücken entnommene) und literarische Texte untergliedert sind. Während diese textsortenspezifische Gliederung vorbildlich ist, kann diese Untersuchung natürlich nur begrenzt Aussagen über das heutige Chinesisch bieten.
2.6 Liste der Chinesischkorpora
In der folgenden Liste sind die umfangreichsten und am häufigsten zitierten Korpora für Chinesisch aufgeführt, die über das Internet 2017 zugänglich sind.
Die Einteilung in schriftliche und mündliche Korpora erfolgt anhand des Mediums der Primärdaten. Demzufolge können schriftliche Korpustexte auch konzeptionell mündliche Äußerungen und Texte wie informelle Briefe enthalten. Die mündlichen Korpora umfassen Aufzeichnungen mündlicher Kommunikation, welche im Zuge der Korpuserstellung in Form von Transkripten schriftlich fixiert und annotiert wurden. Meist stehen neben diesen Transkriptionen auch Audiodateien der Aufnahmen zur Verfügung (vgl. Storrer 2011, S. 226). Da die meisten mündlichen Korpora aus Datenschutzgründen nicht öffentlich zugänglich sind, wurden, um eine repräsentative Darstellung der vorhandenen Korpora zu gewährleisten, auch diejenigen mündlichen Korpora für das Chinesische aufgenommen, die häufig rezipiert werden, jedoch nur auf Nachfrage zugänglich sind oder eine Lizenz benötigen. Diese können über die entsprechenden Links in der Liste erworben werden.
Übersicht einiger öffentlich zugänglichen Korpora für geschriebenes Chinesisch
| Name | Umfang | Link | Anmerkungen |
| UCLA Lancaster Corpus of Mandarin Chinese LCMC1 & LCMC2 1991 / 2012 Tony McEnery; Richard Xiao; Hongyin Tao | LCMC1 und LCMC2: 1 Millionen Wörter 500 Texte 15 Textsorten Mainland China | https://www.lancaster.ac.uk/fass/projects/corpus/LCMC/ | Zugang nur nach Registrierung / Download (bisher nicht geprüft) |
| ToRCH Texts of Recent CHinese 2019 现代汉语平衡语料库 Beijing Foreign Studies University 2019李佳蕾、孙铭辰、许家金 | 2009 / 2014 / 2019 2 Mio. Wörter 671 Texte 15 Textsorten | https://corpus.bfsu.edu.cn/info/1082/1782.htm = Kopie des Lancaster Corpus? | – Brown family Corpus |
| CCL Corpus Peking University: Center of Chinese Linguistics PKU 2003 Weidong Zhan; Rui Guo; Yirong Chen | 字符数: 783,463,175 其中 现代汉语语料 581,794,456 古代汉语语料 201,668,719 Integration weiterer Korpora (u.a. CWAC 中文学术文献语料库) | http://ccl.pku.edu.cn:8080/ccl_corpus/ darin 10.645 Schriftzeichen nach Häufigkeit: http://ccl.pku.edu.cn:8080/ccl_corpus/xiandai_char_info.pdf (18.898 verschiedene Schriftzeichen in klassischen Texten) | – am häufigsten verwendet – Handhabung nur in Chinesisch Kritik: – Kein ausgeglichenes Korpus – Seite funktioniert manchmal nicht |
| Chinese National Corpus (CNC) China State Language Commission | 12 Millionen Wörter | http://www.aihanyu.org/cncorpus/CnCindex.aspx 2023 nicht zugänglich | – Handhabung in Chinesisch – relativ ausgewogener und repräsentativer Korpus |
| Academica Sinica Balanced Corpus of Modern Chinese 4.0 (Sinica Corpus) 2010 Keh-Jiann Chen; Chu-Ren Huang | primär taiwan. Chinesisch: Artikel von 1981-2007. 語料庫共有 19,247 篇文章;1,396,133句數;11,245,330 個詞數 (word token) ;239,598 個詞形 (word type); 17,554,089 個字數 (character token) | http://asbc.iis.sinica.edu.tw/ | Repräsentative Stichprobe des Modernen Chinesisch – Handhabung in Chinesisch – Englische Anleitung ist vorhanden Wortartenzuweisung mit Codes |
3. Fazit
Im Internet sind mehrere Chinesischkorpora öffentlich zugänglich, die je nach Forschungszweck und Erkenntnisinteresse variieren, die mit unterschiedlichen Funktionen und Annotationskategorien ausgestattet sind und über verschiedene sampling frames verfügen. In der Forschungsliteratur häufig erwähnte Korpora wurden in oben stehender Übersicht zusammengestellt, um die Suche nach einem geeigneten Korpus für eigene Forschungszwecke zu erleichtern.
Die Verwendung von Chinesischkorpora unterstützt und vereinfacht die sprachwissenschaftliche Forschung zur realen Verwendung des Chinesischen, und zahlreiche Fragen bezüglich der chinesischen Sprache können mithilfe von korpuslinguistischen Verfahren beantwortet werden. Auch für die Fremdsprachendidaktik können korpusbasierte Forschungsergebnisse wegweisend für curriculare Inhalte oder bei der Entwicklung von Übungsformen sein.
Göttingen 2018, Alice Cheng / Andreas Guder
Literatur
Beijing Yuyan Xueyuan Yuyan Jiaoxue Yanjiusuo (北京语言学院教学研究所) (1986): Xiandai Hanyu pinlü cidian. Beijing: Beijing Yuyan Xueyuan Chubanshe.
Lemnitzer, L./Zinsmeister, H. (2015): Korpuslinguistik. Eine Einführung. 3. Auflage. Tübingen: Narr A. Francke.
McEnery, T./Hardie, A. (2012): Corpus Linguistics. Method, Theory and Practice. New York, Cambridge University Press.
Storrer (2011): Korpusgestützte Sprachanalyse in Lexikographie und Phraseologie. In: Knapp, K./Antos, G./Becker-Mrotzek, M./Deppermann, A./Göpferich, S./Grabowski, J./Klemm, M./ Villiger, C. (Hg.): Angewandte Linguistik. Ein Lehrbuch. 3. Auflage. Tübingen: Narr A. Francke Verlag, S. 216-239.
Xu, J./Wu, L. (2014): Web-based fourth generation corpus analysis tools and the BFSU CQPweb case, Waiyu Dianhua Jiaoxue [Computer-assisted Foreing Language Education]. Online verfügbar unter: http://111.200.194.212/cqp/ucla2/, zuletzt geprüft am 30.08.2018.