(1) Evaluate your test results.
- What method(s) did you use to evaluate the results of your usability tests?
How did you evaluate the results?
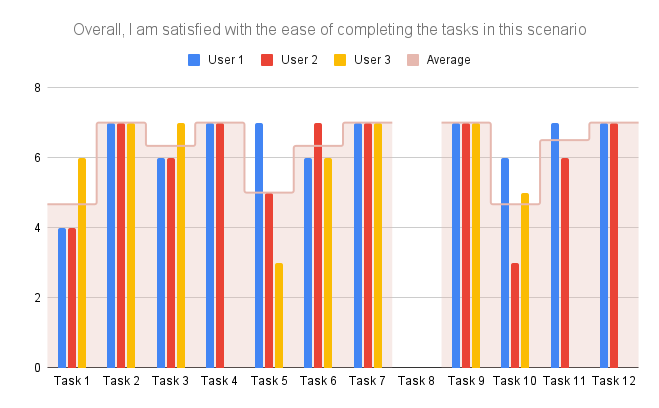
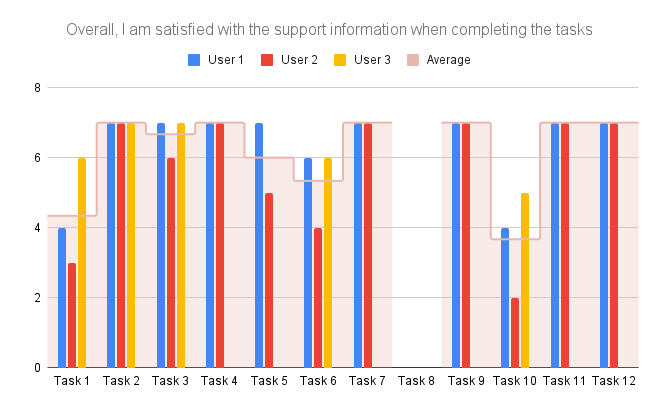
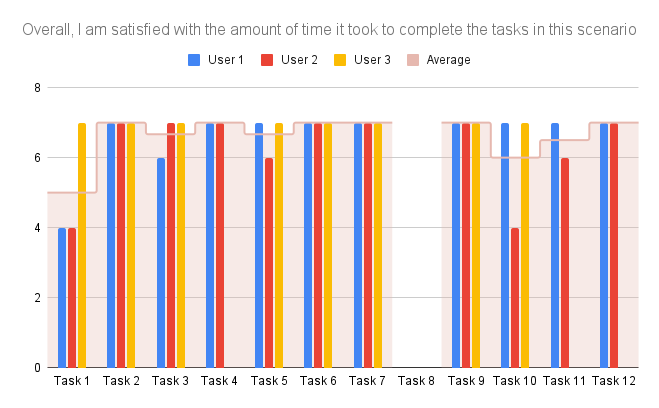
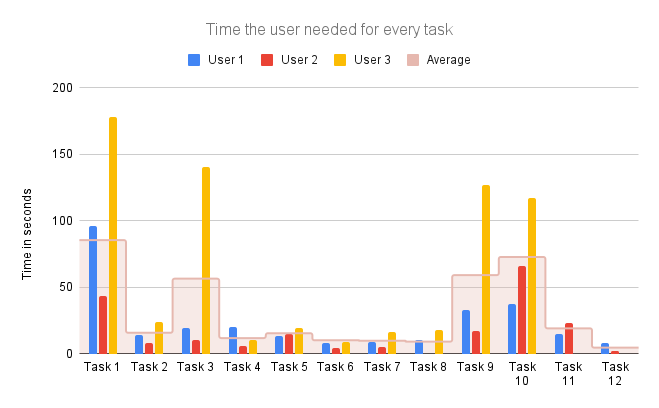
Wir haben die Verbesserungsvorschläge und Kritik am Prototypen der Testpersonen zusammengefasst und systematisch aufgeschrieben. Die Task Completion Rate weiter auszuwerten war nicht sinnvoll, weil alle Personen alle Tasks abgeschlossen hatten.
- What did you learn from the testing?
Es macht einen großen Unterschied, ob man aus der Entwickler-Perspektive auf oder von außen auf den Prototypen schaut. Der Nutzer versteht eventuell Gedanken hinter Funktionen und Funktionsweisen nicht die für uns klar waren. Die Verbesserungsvorschläge von außen waren auch sehr hilfreich.
- What are your main takeaways?
Testen ist gleichzeitig schwierig aber auch sehr wichtig. Auch sollte man relativ früh anfangen, damit Veränderungen noch leicht möglich sind. Die Aufgabenstellung für den Test ist relevant um möglichst aussagekräftige Ergebnisse zu produzieren.
(2) Project description
One image (1000×500 px, png), which shows your prototype:
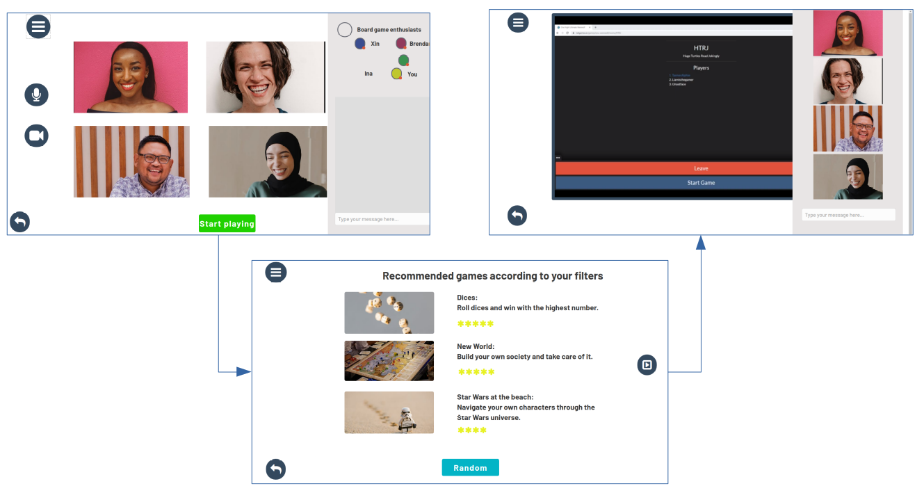
One image (200×200 px, png), which shows some unique part(s) of your project or prototype in a very detailed way (e.g., some logo or part of a screen):
Name of your project + tagline/sub-line:
Social Gaming – no more messy remote board game nights
Project description text:
We are big fans of fun, relaxed board game nights with our friends. However, during the pandemic we experienced that remote version of the board game nights often turned out to be more frustrating than fun: switching between all the different websites, not knowing which games have an online version,…
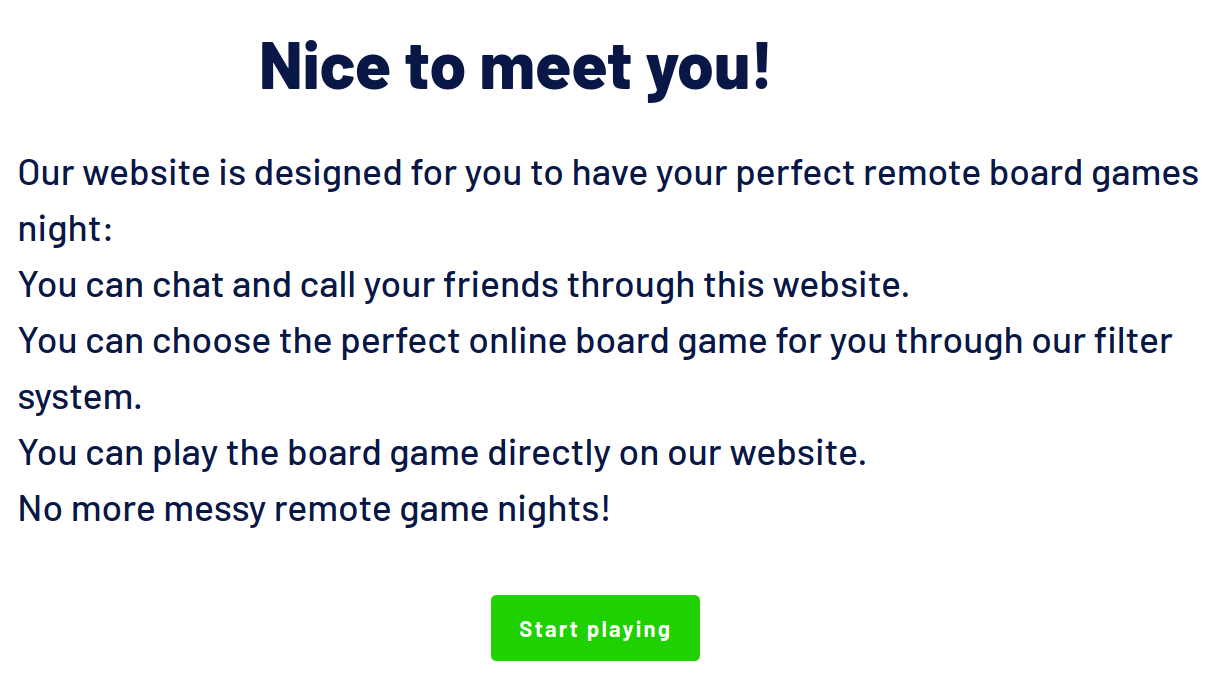
With Social Gaming, we want to transform remote board game nights into a great time with your friends instead of an exhausting evening. To achieve this goal, Social Gaming consists of three core elements:
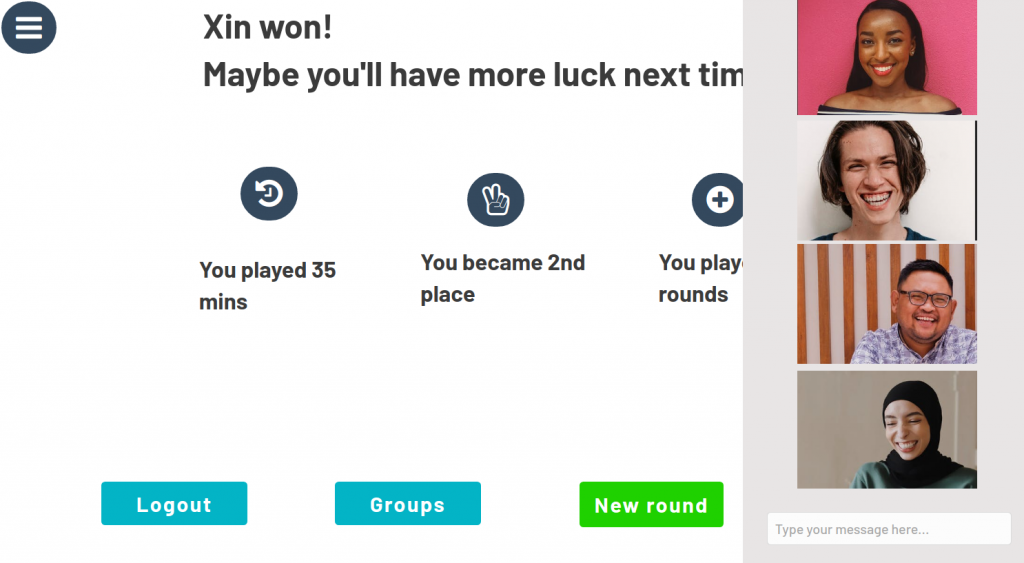
- You are able to audio-, video chat and message your friends over our platform
- You can filter all the online versions of the board games from our many partners exactly according to your needs
- You can play the board games embedded on our website.
To conclude: With Social Gaming your whole game experience will take place on one website, and one website only – no more messy remote board game nights!
3-5 additional images:
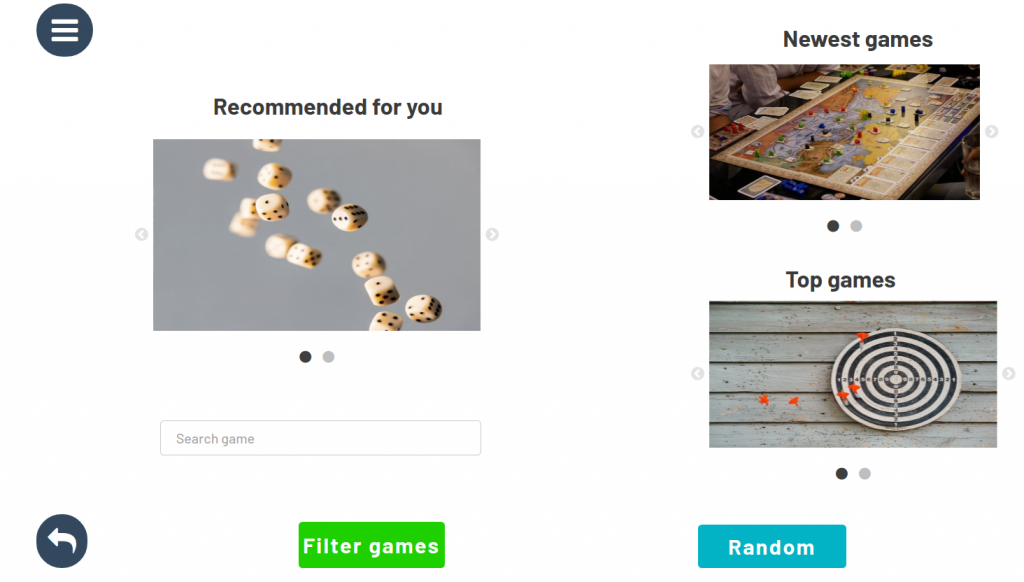
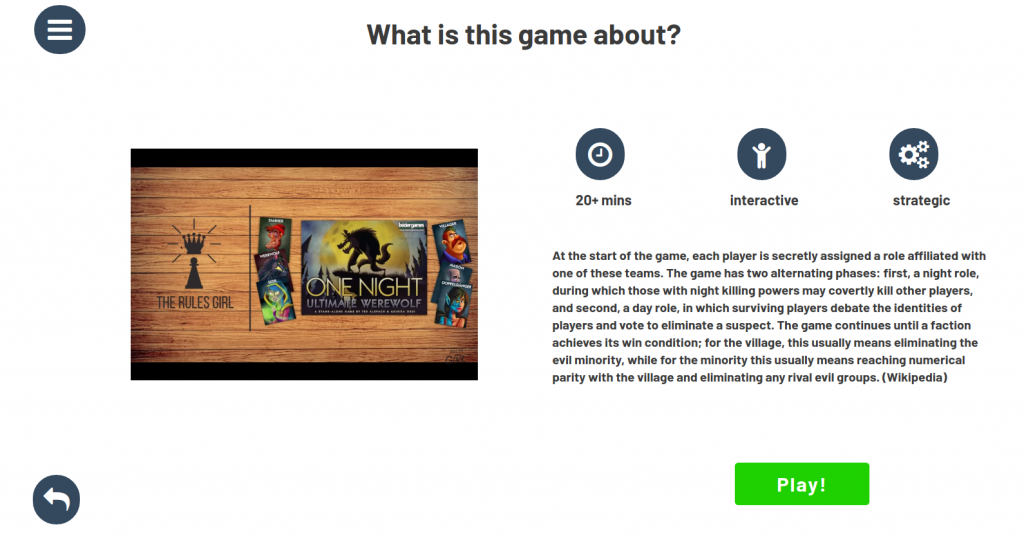
Link to your GitHub/GitLab repo: